Using Spark with GPFS on the ACCRE Cluster
Motivation
Spark is a very versatile tool for big data applications because:
- it distributes jobs transparently to the application
- there’s no MPI programming to worry about; nodes communicate via
ssh - it runs locally, on distributed filesystems, or HDFS
This last point is key, because ACCRE’s HPC cluster utilizes a distributed, or shared, filesystem for making data available to each node in the cluster. Thus, Spark can send an application to an arbitrary number of nodes and read the necessary data from the distributed filesystem as if it they were present locally. In essence, we’re substituting reads from disk (in the HDFS paradigm) for reads across the network.
In this post, we demonstrate how to analyze files on a shared network drive using Spark. Note that we’re not using the BigData Cluster for this job; rather, we’re running Spark on the production partition of the ACCRE cluster to reveal the inner workings of Spark’s standalone cluster model.
GPFS (General Parallel File System) is a proprietary, resilient, replicated
network files system developed at IBM. The traditional ACCRE HPC Cluster uses
GPFS to share files in the /home, /scratch, and /data. The test application we’re running is wordcount which will be
the subject of another post. Feel free to follow along with the code repo.
SLURM Configuration
SLURM is the scheduler and resource manager utilized on the ACCRE HPC cluster, and in order to provision a cluster on SLURM, we have to go through SLURM. The credit for working out most of the logic goes to this post on serverfault.
The mechanics of launching a Spark cluster are a little more complicated than
most SLURM workflows, but the idea is pretty straightforward: we request a SLURM
job using sbatch that blocks out all the resources we’ll need for starting the
cluster. Within this allocation, we’re going to launch a Spark standalone cluster,
which has the distinct roles of Client, Master, and Worker. The code that each of these
roles execute is defined with the task-roles.sh shell script; this script takes
a single argment that indicates which role is intended to be executed. Let’s look at
the sbatch job and these roles in depth.
Provisioning resources with SLURM
The resource request for our Spark cluster is provisioned through the SLURM script
batch-job.slurm; this script requests, along with memory and time, a total of
8 tasks corresponding to one task for the Client,
one task for the Master, and an six tasks for Workers. Currently,
SLURM only supports homogeneous resource allocation, so there’s no way to customize
the resources depending on the task type. It’s a little bit of waste of resources,
but it’s pretty much necessary at this point.
#!/bin/bash
#SBATCH --ntasks=8
#SBATCH --cpus-per-task=2
#SBATCH --time=00:10:00
#SBATCH --mem-per-cpu=8G
#SBATCH --partition=debug
# Create a directory on /scratch to hold some info for this job
export JOB_ID=$SLURM_JOB_ID
export JOB_HOME="/scratch/$USER/$JOB_ID"
echo "JOB_HOME=$JOB_HOME"
mkdir -p $JOB_HOME
export NWORKERS=$(( $SLURM_NTASKS - 2 ))
echo "NWORKERS=$NWORKERS"
export LAST_PROC=$(( $SLURM_NTASKS - 1 ))
In addition to the SLURM directives requesting resources,
there are a number of global variables set in batch-job.slurm
which are necessary to configure the Spark setup. The number of cores and memory
allocated to the Spark job are calculated here, which prevents Spark from
grabbing more resources than SLURM has allocted. So, in order to ecreate a larger
cluster, just change the SBATCH directives for ntasks and, possibly, mem-per-cpu.
# Don't mess with these unless you know what you are doing
export SPARK_WORKER_CORES=$SLURM_CPUS_PER_TASK
export SPARK_DAEMON_MEMORY=$(( SLURM_MEM_PER_CPU * $SLURM_CPUS_PER_TASK - 1000 ))m
export SPARK_MEMORY=$SPARK_DAEMON_MEMORY
# These are the defaults anyways, but configurable
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8080
# Load the Spark package
setpkgs -a spark_2.1.0 # sets JAVA_HOME and SPARK_HOME
# Try to load stuff that the spark scripts will load
source "$SPARK_HOME/sbin/spark-config.sh"
source "$SPARK_HOME/bin/load-spark-env.sh"
Once our enviroment is set, we want to launch parallel tasks for our Client, Master,
and Workers using SLURM’s srun command . To do this, we use the --multi-prog option
of srun, which allows specifying different exectuables for each task using
a plain-text config file. Rather than updating this file every time we
wish to change the number of tasks (with our #SBATCH directives),
we simply generate this file on the fly from within the batch-job.slurm script:
# Create the configuration file specific to this batch job
cluster_conf=$"# This file has been generated by $0\n"
cluster_conf+=$"0 ./task-roles.sh CLIENT\n"
cluster_conf+=$"1 ./task-roles.sh MASTER\n"
cluster_conf+=$"2-$LAST_PROC ./task-roles.sh WORKER"
echo -e $cluster_conf > cluster.conf
The file cluster.conf contains on each line a task number or range of task numbers
and the executables to be run on those tasks:
# This file has been generated by /usr/spool/slurm/job12609822/slurm_script
0 ./task-roles.sh CLIENT
1 ./task-roles.sh MASTER
2-7 ./task-roles.sh WORKER
Finally, we pass the cluster.conf filename to srun:
# Start the CLIENT, MASTER, and WORKERS
srun -l -o slurm-%j-task-%t.out --multi-prog cluster.conf
In the next section, we’ll look at what each of these tasks actually does.
Assiging roles to tasks
The file task-roles.sh stores the executable code called by srun for each process
in our job.
The Client
The first code block that encapsulates one level of our recursion is the Client block.
The Client block starts with exporting the SLURM_JOB_ID of the client and a number of
Spark-specific variables, and because these variables are exported, they will be
available to the child processes (SLURM jobs) that we start from Client.
If we don’t specify a node to SLURM, then we don’t know a priori on which node
the Master job will land. So, instead, we wait for the Master to write its URL to
a GPFS-shared drive, in this case $JOB_HOME/master_url. The Client waits for
the master to write to this location with a timeout of 100 seconds.
if [ $LEVEL == "CLIENT" ]; then
# Wait for the master to signal back
getMasterURL
echo "Master Host: $MASTER_HOST"
msg1="To tunnel to MasterUI and JobUI -> ssh "
msg1+="-L $SPARK_MASTER_WEBUI_PORT:$MASTER_HOST:$SPARK_MASTER_WEBUI_PORT "
msg1+="-L 4040:$MASTER_HOST:4040 "
msg1+="$USER@login.accre.vanderbilt.edu"
echo $msg1
# Wait for workers to signal back
confirmWorkers
# Submit the Spark application, as defined in APP
$SPARK_HOME/bin/spark-submit \
--master $MASTER_URL \
--deploy-mode client \
--total-executor-cores $(( NWORKERS * $SPARK_EXECUTOR_CORES )) \
$APP
The function getMasterURL waits for the Master to write to Workers, and
once it does, it sets the variable MASTER_URL:
# Reads the master URL from a shared location, indicating that the
# Master process has started
function getMasterURL {
# Read the master url from shared location
MASTER_HOST=''
i=0
while [ -z "$MASTER_HOST" ]; do
if (( $i > 100 )); then
echo "Starting master timed out";
exit 1
fi
sleep 1s
local flag_path=$JOB_HOME/master_host
if [ -f $flag_path ]; then
MASTER_HOST=$(head -1 $flag_path)
else
echo "Master host not yet intialized"
fi
((i++))
done
MASTER_URL="spark://$MASTER_HOST:$SPARK_MASTER_PORT"
}
The function confirmWorkers waits for all Workers to write their process IDs to
a shared location and then releases execution back to the calling script:
# Reads files named after worker process IDs
# Once each worker has written its hostname to file,
# this function terminates
function confirmWorkers {
local i=0
while (( i < $NWORKERS )); do
i=0
for w_procid in `seq 2 $LAST_PROC`; do
echo "Checking for workers"
if [ -f $JOB_HOME/$w_procid ]; then
(( i++ ))
fi
done
sleep 1s
done
}
Note that we create directories to keep all the job output together under our a parent directory named after the Client’s job ID.
Once the setup is out of the way, we’re ready to allocate and launch a SLURM job that will run Spark Master program. Here, we’re providing 10G of memory on a single node to run the Master.
Once the Workers are up, we are ready to submit our job using spark-submit. The
options we’re passing to the spark-submit specify the address of the Master and
that the driver will run on the Client node.
# TODO: Optionally, wait for workers to signal back
sleep 5s
# Specify input files
INPUT="README.md"
OUTPUT="wordcount_$(date +%Y%m%d_%H%M%S)"
APP="spark-wc_2.11-1.0.jar"
# Submit the Spark jar
$SPARK_HOME/bin/spark-submit \
--master $MASTER_URL \
--deploy-mode client \
$APP $INPUT $OUTPUT
# Tear down the master and workers
scancel $MASTER_JOB_ID
scancel $WORKERS_JOB_ID
At the end of the Client job, we cancel the SLURM jobs for the Master and Workers since they would otherwise continue running until reaching their time limit.
The Master
elif [ $LEVEL == MASTER ]; then
export SPARK_MASTER_HOST=$(hostname)
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8080
export MASTER_URL="spark://$SPARK_MASTER_HOST:$SPARK_MASTER_PORT"
export MASTER_WEBUI_URL="spark://$SPARK_MASTER_HOST:$SPARK_MASTER_WEBUI_PORT"
# Try to load stuff that the spark scripts will load
source "$SPARK_HOME/sbin/spark-config.sh"
source "$SPARK_HOME/bin/load-spark-env.sh"
# Write the master url to shared disk so that the client can read it.
echo $MASTER_URL > $JOB_HOME/master_url
# Start the Spark master
$SPARK_HOME/bin/spark-class org.apache.spark.deploy.master.Master \
--ip $SPARK_MASTER_HOST \
--port $SPARK_MASTER_PORT \
--webui-port $SPARK_MASTER_WEBUI_PORT
The Worker
We force the Workers to wait on the Master to broadcast its URL before they start themselves, even though Workers will automatically retry if the master URL is not specified. Then, we simply need to start the worker through its class.
elif [ $LEVEL == "WORKER" ]; then
getMasterURL
export SPARK_WORKER_DIR=/tmp/$USER/$JOB_ID/work
export SPARK_LOCAL_DIR=/tmp/$USER/$JOB_ID
mkdir -p $SPARK_WORKER_DIR $SPARK_LOCAL_DIR
echo "Master URL = $MASTER_URL"
hostname > $JOB_HOME/$SLURM_PROCID
# Start the Worker
"$SPARK_HOME/bin/spark-class" \
org.apache.spark.deploy.worker.Worker $MASTER_URL
Running the job
To kick things off, all that’s necessary is sbatch batch-job.slurm. Once the job
launches, a series of output files will be generated, one for each task and one for
the parent batch job itself.
In your slurm-#########-task-0.out file, you’ll see the instructions for port
forwarding the Spark UIs to you local machine.
Simply run these commands from a new terminal session, for instance:
ssh -L 8080:vmpXXXX:8080 -L 4040:vmpXXXX:4040 vunetid@login.accre.vanderbilt.edu
The Spark Master UI
In your favorite web browser, navigate to localhost:8080;
this UI is useful for making sure that your cluster has been set up appropriately.
It lists the wokers deployed, their memory allocation, and any jobs running on the
cluster:
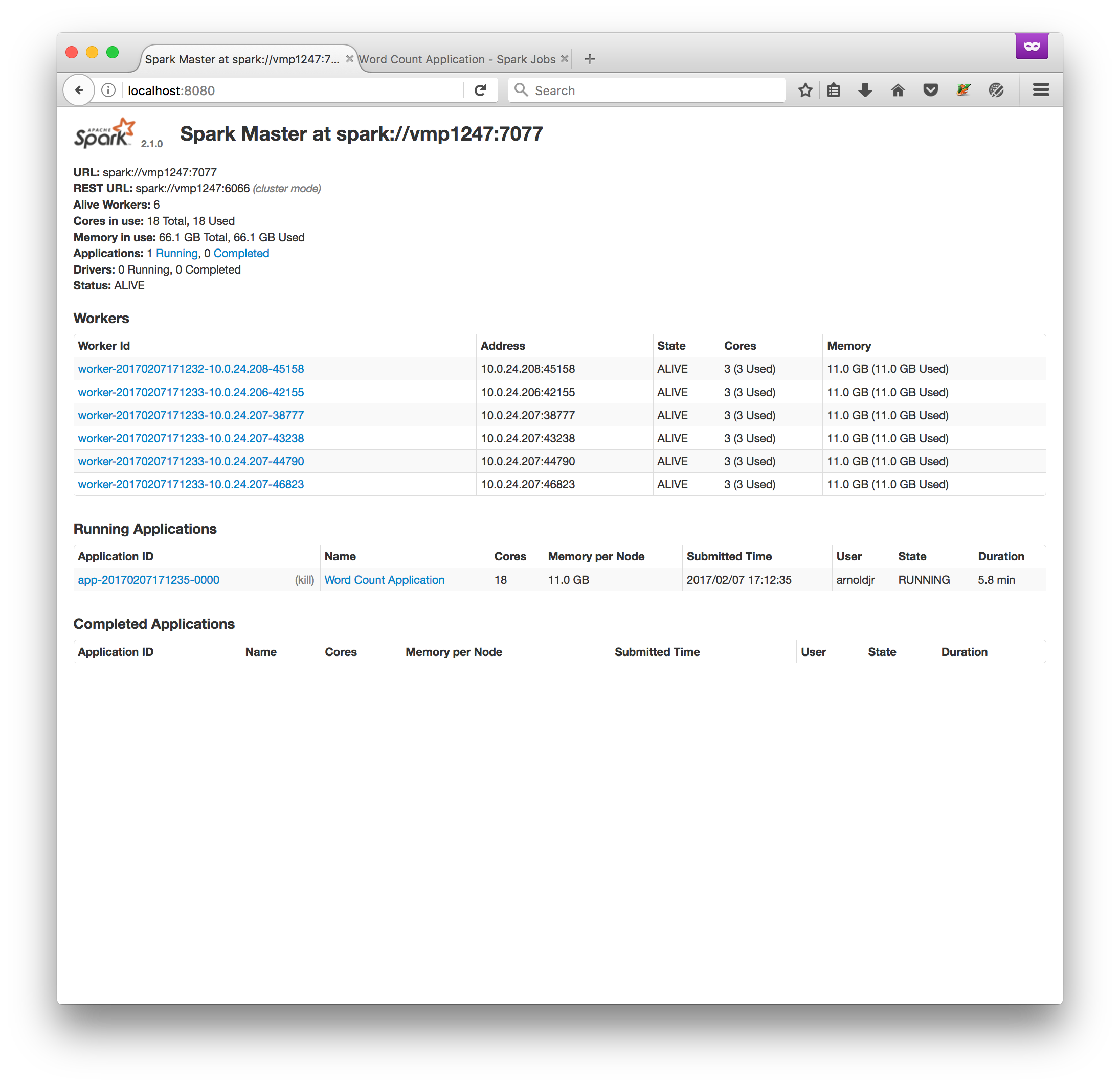
The Spark Job UI
At localhost:4000 you’ll find this UI (provided a job is running):
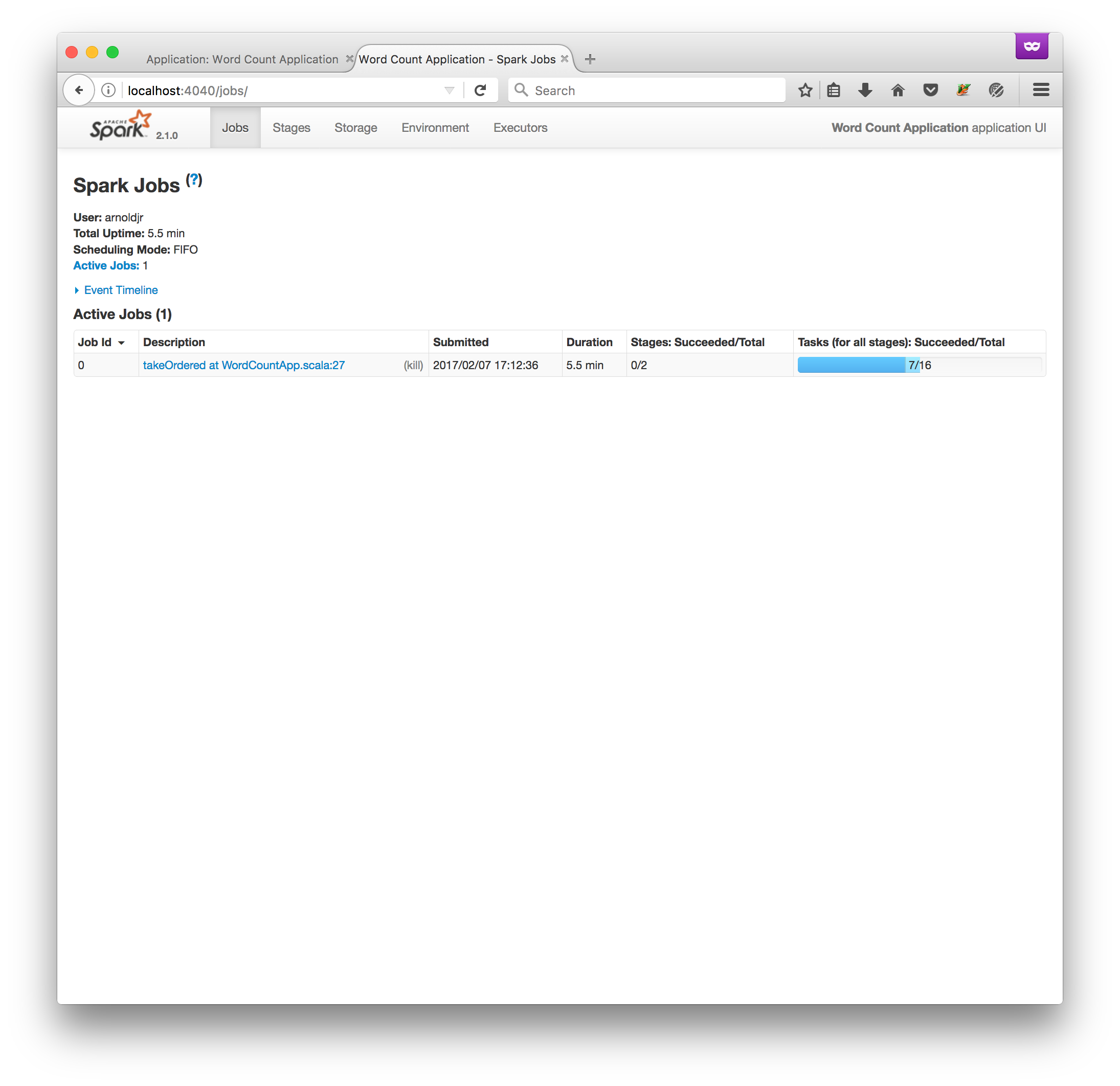 This UI is particularly cool because it renders nice SVG graphics depicting the all
the steps of your job:
This UI is particularly cool because it renders nice SVG graphics depicting the all
the steps of your job:
And finally, here’s a video clicking through the web UIs, but trust me, it’s much more fun to look at your own job.
Final thoughts
Since we’ve started the Master and Workers as non-terminating jobs, the SLURM job will run until the time limit is reached or until the job itself is cancelled. There’s no reason the client is limited to a single job submission, however.
Running Spark on top of SLURM might be useful for researchers who’ve already got lots of data stored on a shared filesystem on the cluster and don’t really want to move it to HDFS and back again. It’s easy to imagine a number of one-off jobs that a researcher could construct to analyze their data, and Spark provides a convenient way of composing those jobs quickly.